Its five years with no limitations, so when you are due to be released; Whats your password? Another five years... Its such a poorly worded law you could literally spend your life in prison for forgetting your password. And Its mostly used against peaceful protesters.
Double jeopardy was abolished by Blair in the Criminal Justice Act 2003, Scotland abolished it as well a bit later in Double Jeopardy Act 2011. However i doubt it would apply even if we had it as the wording in Section 49 is so poor it could just be reissued as a new offense each time.
Has it happened? Section 49 of the Regulation of Investigatory Powers Act 2000 has a secrecy requirement built into it, where if you tell anyone that you have been issued a Section 49 you can get an additional 5 years (treated as a separate crime). This, as you can imagine, makes your question difficult to answer.
It does and of course it's different happened. My pet peeve has to be the "it's a poorly worded law" argument about things that have obviously been considered by legal experts. The scares like "the psychoactive substances act will technically make coffee illegal" I've seen on HN are particularly egregious.
I don’t believe this is the case, every now and then we see prosecutors using an obsolete unenforced law or an unexpected edge case of some law to come after people.
A great example is the CFAA. It has been judicially narrowed after court battles, because in its original form it was overbroad and criminalized basic, common things. Prosecutors abused it in order to get political wins until they were finally stopped.
This is unfortunately fairly common. Legislators either push for too much or don’t understand how the law might be applied, and innocent people suffer until someone wins a big expensive set of appeals.
Edit: I realize now you may be talking about the UK in particular, in which case you don’t even get this shoddy level of protection as “Parliament is sovereign” (lol).
I'm talking about the specific law that was being discussed, and the particular other law I used as an example. And the protection mentioned was the one of double jeopardy which had also been explicitly mentioned.
Double jeopardy was partially eliminated in the UK in 2003 for qualifying offenses. I don’t think this has been tested, but during a retrial, a refusal to provide a password would be a separate RIPA offense from any refusal during the first trial. So you could actually be jailed more than once for this. For qualifying offenses all that is required for a retrial is “new and compelling evidence” which is a low hurdle for politically unpopular defendants.
If that did happen you'd have a good case from the Human Rights Act because it becomes indefinite imprisonment. The UK is still following the ECHR as well.
But arguing these theoretical untested-because-they-never-happen edge cases isn't exactly pushing forward a good case for this law having been "badly written." There's seemingly no problem with it in practice.
Dismissing the concerns about poorly worded laws on the basis that they have been considered by legal experts is laughable when it's often legal experts, and in the case of the Psychoactive Substances Act, the government's own advisors that are the ones raising concerns with the broad applicability and unenforceable nature of these controversial laws. The Psychoactive Substances Act has an explicit exemption stating food is not covered by the law for crying out loud, and the exemption for healthcare providers to act within the course of their profession was only added as an amendment, it wasn't even considered in the original drafting of the bill.
> The Psychoactive Substances Act has an explicit exemption stating food is not covered by the law for crying out loud,
Why the "for crying out loud?" That's an example of the law being well written in a way that covers the knee jerk reactions to "it's too broad, it's badly written!"
> the government's own advisors that are the ones raising concerns with the broad applicability
What's your issue with this? They're advisors, it's their job to raise concerns that lead to the inclusion of exemptions like the one you're "crying out loud" about.
> it wasn't even considered in the original drafting of the bill.
That's why bills go through various stages of drafting and debate, and why parliament seeks out and considers the advice from industry. It's "laughable" to judge the quality of a law by the original draft, just as it would be too judge a piece of software by the initial commit.
I'm not even sure how much practical difference there is between 5 and indefinite in practice, 5 years is a long time. I imagine it is pretty life-destroying. Especially for the crime of having something on your phone that you want to keep private.
> If it’s not about nation security or CSAM, it’s two.
I am sure we all get what you mean, but there is a comic interpretation in vaguely-Soviet style here where if someone hasn't done anything wrong they only get 2 years. I'm going to spend some time this weekend making sure my encryption is plausibly deniable where possible.
It's not okay to imprison people for 5 years vs lifetime, but at the same time, facts matter, and we shouldn't get in the habit of allowing fibs to slip through just because they're directionally correct.
The police must obtain appropriate permission from a judge to obtain a s.49 RIPA notice.
Before a judge grants the notice, they must be satisfied that:
The key to the protected information is in the possession of the person given notice.
Disclosure is necessary in the interest of national security, in preventing or detecting crime or in the interests of the economic wellbeing of the UK.
Disclosure is proportionate.
If the protected information cannot be obtained by reasonable means.
> So you're saying it's still at the discretion of a single magistrate?
A judge isn't a magistrate, but also: No, of course not. There are different layers of legal protections in the UK. You would be able to appeal the notice itself, you would be able to argue at the court against the decision, and you could make an appeal to a higher court if your were convicted. Furthermore you could make an official complaint about the investigation afterwards.
An interesting observation of the West is that people have an innate trust in the authorities/institutions. It's largely because the institutions have been well run for so long. But as that fades we're left in this twilight zone where you can point to a law like it prevents something. As is often pointed out, the Soviet constitution was much more free than the US one. Even the Romans knew this distinction
> people have an innate trust in the authorities/institutions. It's largely because the institutions have been well run for so long.
There isn't trust of the institutions in the UK. That's why there's so many layers of checks and balances like various courts of appeal and the two houses in the parliament. It's designed with the idea that a rogue player can't go wild.
It's also not true that British institutions have been well run for a long time. Bloody Sunday would be a very visceral and obvious example. Interesting case as well because obviously it took almost half a century but at least there was official recognition and apology from the prime minister after the courts and parliamentary investigative bodies did their thing.
The standard of proof is reasonable grounds, don't forget your passwords because this is an incredibly low bar to pass.
>in preventing or detecting crime
If the police are requesting a s.49 notice it goes without saying that it will be for preventing or detecting crime, but notices can also be issued to ensure the exercise or performance of public bodies, statutory powers, or statutory duties without such a requirement.
>Disclosure is proportionate.
In regards to what is sought to be achieved by the disclosure. It is not disproportionate to request disclosure for the purpose of preventing or detecting crime regardless of how benign that crime is.
>If the protected information cannot be obtained by reasonable means.
The law has been used against people for failing to give up Facebook passwords. The police routinely ask companies for information without a warrant and they're usually legally denied such requests based on GDPR grounds. 'Reasonably practicable' means nothing if it can be bypassed by police trying their luck without a warrant.
> People have been jailed for hate speech in the uk
The parent poster claimed "for liking a post".
The cases I've seen of "jailed for hate speech" tend to wind up having a harassment or incitement component to them. https://www.bbc.com/news/articles/cy76dxkpjpjo as an example. Hence the request for a cite.
"Parlour, of Seacroft, Leeds, who called for an attack on a hotel housing refugees and asylum seekers on Facebook, became the first person to be jailed for stirring up racial hatred during the disorder."
How convenient that the government doesn't make the numbers public and then have to issue statements like this when journalists do some digging on the matter
I don't get what you're trying to say here? Yes, there are real issues with the government arresting people for speech, and the number is going up, but that's not proof for the specific claim of "you can be imprisoned for liking a post [...]". You can't just tack on spurious claims onto a more well supported claim on the basis that the former is directionally the same as the latter.
You're in a place called "Hacker" news, many of us hackers feel like we shouldn't be forced to unlock our private devices, not sure this is surprising.
Criticizing democracies with the policies of a police state is Nazi behavior? I’m lost. AFAIK Nazis are associated with those supporting authoritarian regimes not those criticizing the slide into authoritarianism. You even yourself put up a link about someone convicted who had to go through a long legal battle to get their freedom. The claim may have been overbroad in terms of the powers the state has, but they were off only in magnitude what RIPA2000 outlines as powers.
How is "against democracies" even on topic here? Parent commentator said HK is now like the UK, why it matter how much of a democracy either of the places are?
And no, it isn't a "nazi bar" just because someone disagrees with you, that's not how that label should be applied. Save it for actual nazis, otherwise you're doing the rest of us a huge disservice, as when there are actual nazis, people think we're talking opinions rather than facts. As a human who despise nazis and fascists, please don't contribute to making the world worse.
I strongly disagree with the parent poster, but they are deploying a specific term. Nazi Bar doesn't imply everyone within is a Nazi. It implies a bar that permits a Nazi to stay and drink. That Nazi will come back later with their friends who are also Nazis, and over time the bar will increasingly become funded by Nazis.
It's really really strange to use here, however, because this thread is about not giving in to authoritarianism. If you want to see intolerance, this person should go look at the recent transgender athletes thread. That post might actually be a "Nazi bar".
Because the original commenter is screaming about how the UK is authoritarian without any links, which smells to me like he's a typical right wing idjit, who wants to put in Nigel Farage in power and actually turn the place more Nazi.
That's why I asked if he was referring to that overturned conviction, which shows there's still some rule of law, or post a link to what the actual hell he's talking about.
Pfft, but well, fuck me, just learned that I'm the idiot who's wrestling with the pig yet again.
The destination of the packet where it is sent, just as a toy sent from the U.S. to a customer in the U.K. is sent to the U.K. rather than the local Fedex store.
> following a highly publicised mass-murder of children which was (entirely wrongly) being blamed on asylum seekers.
The mass-murder was a consequence of the asylum system. Given what is publicly known, parents of Axel Rudakubana were overwhelmingly likely to have been asylum seekers.
Using LM-Studio as the frontend and Playwright-powered MCP tools for browser access. I've had success with one such MCP: https://github.com/instavm/coderunner It has a tool called navigate_and_get_all_visible_text, for example.
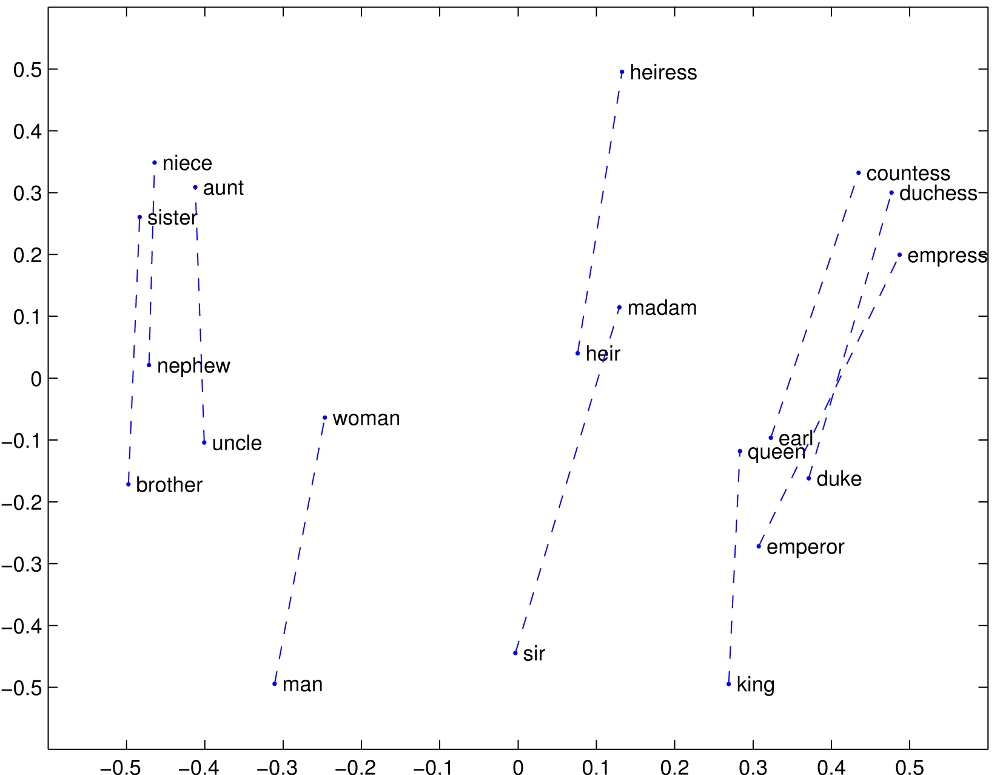
> The 2D map analogy was a nice stepping stone for building intuition but now we need to cast it aside, because embeddings operate in hundreds or thousands of dimensions. It’s impossible for us lowly 3-dimensional creatures to visualize what “distance” looks like in 1000 dimensions. Also, we don’t know what each dimension represents, hence the section heading “Very weird multi-dimensional space”.5 One dimension might represent something close to color. The king - man + woman ≈ queen anecdote suggests that these models contain a dimension with some notion of gender. And so on. Well Dude, we just don’t know.
nit. This suggests that the model contains a direction with some notion of gender, not a dimension. Direction and dimension appear to be inextricably linked by definition, but with some handwavy maths, you find that the number of nearly orthogonal dimensions within n dimensional space is exponential with regards to n. This helps explain why spaces on the order of 1k dimensions can "fit" billions of concepts.
Note you don't see arXiv papers where somebody feeds in 1000 male gendered words into a word embedding and gets 950 correct female gendered words. Statistically it does better than chance, but word embeddings don't do very well.
there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall. If you try experiments with N>100 words you go endlessly in circles and produce the kind of inconclusively negative results that people don't publish.
The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word. For instance you can't really build a "part of speech" classifier that can tell you "red" is an adjective because it is also a noun, but give it the context and you can.
In the context of full text search, bringing in synonyms is a mixed bag because a word might have 2 or 3 meanings and the the irrelevant synonyms are... irrelevant and will bring in irrelevant documents. Modern embeddings that recognize context not only bring in synonyms but the will suppress usages of the word with different meanings, something the IR community has tried to figure out for about 50 years.
> there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
While it would certainly have been possible to choose a projection where the two groups of words are linearly separable, that isn't even the case for https://nlp.stanford.edu/projects/glove/images/man_woman.jpg : "woman" is inside the "nephew"-"man"-"earl" triangle, so there is no way to draw a line neatly dividing the masculine from the feminine words. But I think the graph wasn't intended to show individual words classified by gender, but rather to demonstrate that in pairs of related words, the difference between the feminine and masculine word vectors points in a consistent direction.
Of course that is hardly useful for anything (if you could compare unrelated words, at least you would've been able to use it to sort lists...) but I don't think the GloVe authors can be accused of having created unrealistic graphs when their graph actually very realistically shows a situation where the kind of simple linear classifier that people would've wanted doesn't exist.
This is missing the point. What we have is two dimensions* of hundreds, but those two dimensions chosen show that the vector between a masculine word and its feminine counterpart is very nearly constant, at least across these words and excluding other dimensions.
What you're saying, a line/plane/hyper-plane that separates a dimension of gender into male and female, might also exist. But since gender neutral terms also exist, we would expect that to be a plane at which gender neutral terms have a 50/50% chance of falling to either side of the plane, and ideally nearby.
* Possibly a pseudo dimension that's a composite of multiple dimensions; IDK, I didn't read the paper.
> The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word.
In addition to being able to utilize attention mechanisms, modern embedding models use a form of tokenization such as BPE which a) includes punctuation which is incredibly important for extracting semantic meaning and b) includes case, without as much memory requirements as a cased model.
The original BERT used an uncased, SentencePiece tokenizer which is out of date nowadays.
I was working at a startup that was trying to develop foundation models around at time and BPE was such a huge improvement over everything else we'd tried at that time. We had endless meetings where people proposed that we use various embeddings that would lose 100% of the information for out-of-dictionary words and I'd point out that out-of-dictionary words (particularly from the viewpoint of the pretrained model) frequently meant something critical and if we lost that information up front we couldn't get it back.
Little did I know that people were going to have a lot of tolerance for "short circuiting" of LLMs, that is getting the right answer by the wrong path, so I'd say now that my methodology of "predictive evaluation" that would put an upper bound on what a system could do was pessimistic. Still I don't like giving credit for "right answer by wrong means" since you can't count on it.
Don’t the high end embedding services use a transformer with attention to compute embeddings? If so, I thought that would indeed capture the semantic meaning quite well, including the trait-is-described-by-direction-vector.
> In https://nlp.stanford.edu/projects/glove/ there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
Ramsey theory (or 'the Woolworths store alignment hypothesis')
Oh yes, this makes a lot of sense, thank you for the "nit" (which doesn't feel like a nit to me, it feels like an important conceptual correction). When I was writing the post I definitely paused at that part, knowing that something was off about describing the model as having a dimension that maps to gender. As you said, since the models are general-purpose and work so well in so many domains, there's no way that there's a 1-to-1 correspondence between concepts and dimensions.
I think your comment is also clicking for me now because I previously did not really understand how cosine similarity worked, but then watched videos like this and understand it better now: https://youtu.be/e9U0QAFbfLI
I will eventually update the post to correct this inaccuracy, thank you for improving my own wetware's conceptual model of embeddings
It’s the first in a series of three that I can very highly recommend.
> there's no way that there's a 1-to-1 correspondence between concepts and dimensions.
I don’t know about that! Once you go very high dimensional, there is a lot of direction vectors that are almost perfectly perpendicular to each other (meaning they can cleanly encode a trait). Maybe they don’t even need to be perfectly perpendicular, the dot product just needs to be very close to zero.
I would think of it as the whole embedding concept again on a finer grained scale: you wouldn't say the model 'has a dimension of whether the input is king', instead the embedding expresses the idea of 'king' with fewer dimensions than would be needed to cover all ideas/words/tokens like that.
So the distinction between a direction and a dimension expressing 'gender' is that maybe gender isn't 'important' (or I guess high-information-density) enough to be an entire dimension, but rather is expressed by a linear combination of two (or more) yet more abstract dimensions.
> Machine learning (ML) has the potential to advance the state of the art in technical writing. No, I’m not talking about text generation models like Claude, Gemini, LLaMa, GPT, etc. The ML technology that might end up having the biggest impact on technical writing is embeddings.
This is maybe showing some age as well, or maybe not. It seems that text generation will soon be writing top tier technical docs - the research done on the problem with sycophancy will likely result something significantly better than what LLMs had before the regression to sycophancy. Either way, I take "having the biggest impact on technical writing" to mean in the near term. If having great search and organization tools (ambient findability and such) is going to steal the thunder from LLMs writing really good technical docs, it's going to need to happen fast.
Realistically, it's probably the combination of both embeddings and text generation models. Embeddings are a crucial technology for making more progress on the intractable challenges of technical writing [1] but then text generation models are key for applying automated updates.
>nearly orthogonal dimensions within n dimensional space
nit within a nit: I believe you intended to write "nearly orthogonal directions within n dimensional space" which is important as you are distinguishing direction from dimension in your post.
Johnson-lindenstrauss lemma [1] for anyone curious. But you can only map to k>8(\ln N)/\varepsilon ^{2}} if you want to preserve distances within a factor of \varepsilon with a JL-transform. This is tight up to a constant factor too.
I always wondered: if we want to preserve distances between a billion points within 10%, that would mean we need ~18k dimensions. 1% would be 1.8m. Is there a stronger version of the lemma for points that are well spread out? Or are embeddings really just fine with low precision for the distance?
It's not at all a nit. If one of the dimensions did indeed correspond to gender, you might find "king" and "queen" pretty much only differed in one dimension. More generally, if these dimensions individually refer to human-meaningful concepts, you can find out what these concepts are just by looking at words that pretty much differ only along one dimension.
I'm sorry, I don't get your point at all, and have no idea what you mean by "did this". If you asked for an embedding, you would have gotten a 768 (or whatever) dimensional array right?
For word2vec I know that there's a bunch of demos that let you do the king - man + woman computation, but I don't know how you do this with modern embeddings. https://turbomaze.github.io/word2vecjson/
There’s absolutely no reason to believe that the coordinate system of the embeddings would be aligned along the directions of individual concepts, even if they were linear and one dimensional in the embedding space.
> you find that the number of nearly orthogonal dimensions within n dimensional space is exponential with regards to n.
nit for the nit (micro nit!): Is it meant to be "a number of nearly orthogonal directions within n dimensional space"? Otherwise n dimensional space will have just n dimensions.
Is this because we can essentially treat each dimension like a binary digit, so we get 2^n directions we can encode? Or am I barking up totally the wrong tree?
Basically, but it gets even better. If you allow directions of 'meaning' do wiggle a little bit (say, between 89 and 91 degrees to all other directions), you get a lot more degrees of freedom. In 3 dimensions, you still only get 3 meaningful directions with that wiggle-freedom. However in high-dimensional spaces, this small additional freedom allows you to fit a lot more almost orthogonal directions than the number of strictly orthogonal ones. That means in a 1000-dimensional space you can fit a huge number >> 1000 of binary concepts.
Wait, but if gender was composed of say two dimensions, then there'd be no way to distinguish between "the gender is different" and "the components represented by each of those dimensions are individually different", right?
Oh, so I think what it does is take a nearly infinite-dimensional nonlinear space, and transform it into "the N dimensional linear space that best preserves approximations of linear combinations of elements". That way, any two (or more) terms can combine to make others, so there isn't such a thing as "prime" terms (similar to real dictionaries, every word is defined in terms of other words). Though some, like gender, may have strong enough correlations so as to be approximately prime in a large enough space. Is that about right?
Speaking of UMAP, a new update to the cuML library (https://github.com/rapidsai/cuml) released last month allows UMAP to feasibly be used on big data without shenanigans/spending a lot of money. This opens up quite a few new oppertunities and I'm getting very good results with.
>> nit. This suggests that the model contains a direction with some notion of gender ...
In fact, it is likely even more restrictive ...
Even if the said vector arithmetic were to be (approximately) honored by the gender-specific words, it only means there's a specific vector (with a specific direction and magnitude) for such gender translation. 'Woman' + 'king - man' goes to 'queen, however, p * ('king - man') with p being significantly different from one may be a different relation altogether.
The meaning of the vector 'King' - 'man' may be further restricted in that the vector added to a 'Queen' need not land onto some still more royal version of a queen! The networks can learn non-linear behaviors, so the meaning of the vector could be dependent on something about the starting position too.
... unless shown otherwise via experimental data or some reasoning.
That was an issue in 2023? Quite sure C# fixed something similar back in 2012. Is Go still proudly reinventing the wheel, wooden and filled with termites?
How does "lots" quantify, though? There are billions of desktop Windows users. There are tens of millions of desktop Linux users. I expect desktop BSD to go beyond the thousands, but does it reach the hundreds of thousands?
I've always felt like from a purely user perspective desktop BSD doesn't really distinguish itself from Linux. The software stack is essentially the same, and they're both FLOSS so that's not a reason to switch either. Maybe I'm wrong, but the Linux/BSD choice looks a lot less relevant than the Windows/Linux choice.
So if people use desktop BSD because it essentially gives them slightly fuzzier feelings, and they are essentially a rounding error in their user base, is it really fair to criticize Linux developers for not focusing on portability? You can only spend your time once, so do you use it to work on something benefiting your tens of millions of existing Linux users, or something benefiting your thousands of potential BSD users?
The question was if anyone uses BSD as a desktop and the answer is yes people do.
> You can only spend your time once, so do you use it to work on something benefiting your tens of millions of existing Linux users, or something benefiting your thousands of potential BSD users?
I couldn’t care less how the Wayland devs decided to prioritise their time. But it is worth pointing out that Wayland was architected from the ground up to be agnostic. That’s why it’s the polar opposite to the the “batteries included” design of X.
And as others have pointed out, Wayland is available for some BSD already.
The issue with the standard watermark techniques is that they require an output of at least a few hundred tokens to reliably imprint the watermark. This technique would apply to much shorter outputs.
A crude way:
To watermark:
First establish a keyed DRBG.
For every nth token prediction:
read a bit from the DRBG for every possible token to label them red/black.
before selecting the next token, set the logit for black tokens to -Inf, this ensures a red token will be selected.
To detect:
Establish the same DRBG.
Tokenize, for each nth token, determine the red set of tokens in that position.
If you only see red tokens in lots of positions, then you can be confident the content is watermarked with your key.
This would probably take a bit of fiddling to work well, but would be pretty much undetectable. Conceptually it's forcing the LLM to use a "flagged" synonym at key positions. A more sophisticated version of a shiboleth.
In practice you might chose to instead watermark all tokens, less heavy handedly (nudge logits, rather than override), and use highly robust error correcting codes.
It feels like this would only be feasible across longer passages of text, and some types of text may be less amenable to synonyms than others. For example, a tightly written mathematical proof versus a rambling essay. Biased token selection may be detectable in the latter (using a statistical test), and may cause the text to be irreparably broken in the former.
To handle low entropy text, the “adding a smaller constant to the logits” approach avoids having much chance of changing the parts that need to be exactly a particular thing,
Though in this case it needs longer texts to have high significance (and when the entropy is low, it needs to be especially long).
But for most text (with typical amounts of entropy per token) apparently it doesn’t need to be that long? Like 25 words I think I heard?
What if the entire LLM output isn’t used? For example, you ask the LLM to produce some long random preamble and conclusion with your actual desired output in between the two. Does it mess up the watermarking?
{kind=link}
reply